* 본글의 모든 그림은 논문의 본문에서 가져왔습니다.
이번 요약하는 논문은 2017년 CVPR에 소개된 "Global Context-Aware Attention LSTM Networks for 3D Action Recognition" 입니다.
이전에 소개했던 논문과 유사하게 spatial-temporal LSTM 구조에 attention 모듈을 얹은 형태를 띄고 있습니다. 이전 논문과 어떻게 다른지 파악해보며 읽어보면 좋을 듯 합니다.
[출처]Liu, Jun, et al. "Global context-aware attention LSTM networks for 3D action recognition." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
<개요>
LSTM의 경우 sequential data에 대해 높은 성능을 보인다. 반면 행동 데이터의 경우 특정 joint가 중요할 수 있다. 특히 다른 joint에 많은 noise가 껴 있을 경우 학습이 잘 안될 수 있다.
이러한 성질을 반영하기 위해 LSTM에 attention의 구조를 결합할 수 있는 모델을 제안했다.
Globla Context-Aware Attention LSTM Networks(GCA-LSTM) 행동의 시퀀스에서 전반적인 문맥적 정보에 따라 정보가 있는, 즉, 의미가 있는 joint에 집중되도록 한다. 어떤 joint가 informative한 joint인지 분별하기 위해 반복적으로 실행한다.
<알고리즘 설명>
1. Spatio-Temporal LSTM
본 논문은 기본적으로 행동인식을 하기 위해 기존에 존재했던 Spatio-Temporal LSTM구조를 사용한다.
행동인식은 같은 joint의 시간축에 따른 연관성과 다른 joint들의 동일 frame에서의 연관성 모두 중요한 단서가 된다. 이 두가지를 분석하기 위해 2D ST-LSTM이 제안 되었다.

그림과 같이 한 축으로는 joint들을 한 축으로는 frame을 넣어서 학습 시킨다. 현재 값은 frame축을 따라서 이전 값, 그리고 joint 축을 따라 이전 값을 이용해 학습된다.
2. Global Context-Aware Attention LSTM
중요한 정보를 담고 있는 joint와 그렇지 않은 joint를 구분하기 위한 global context memory를 추가한다. 이는 기존의 lstm의 경우 주변 값들을 주로 보게 되기 때문에 전반적인 문맥을 보고 중요 joint를 찾기 위해 추가하는 memory이다.
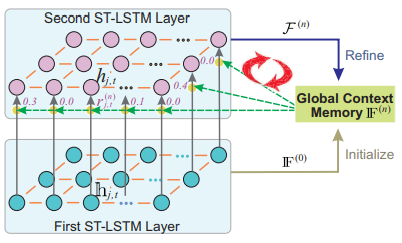
1) Global context memory의 초기화
첫번째 시퀀스에서는 first ST-LSTM의 hidden state 결과를 평균 낸 값으로 F를 초기화한다.
2) Attention in the Second ST-LSTM Layer
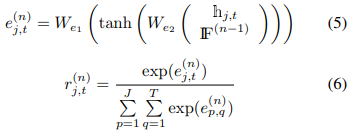
(5),(6)번 식을 통해 attention score를 구한다. 즉 전 global context memory를 통해 얻어진 attention weight가 높으면 높을 수록, 현재 값의 hidden state값이 높을 수록 해당 joint와 frame에 대한 e값이 커지게 되고 이는 곳 r의 값이 커지게 된다. 즉, 해당 frame의 해당 joint의 중요도는 올라간다.

기존의 ST-LSTM의 cell gate 값을 구하는 공식에 r값을 추가하여 특정 joint가 강조되도록 한다. 기존의 ST-LSTM의 cell gate는 (7)번 식에서 r 값이 없이 구해졌다. r을 추가함으로써 해당 frame의 해당 joint의 중요도가 더해지게 된다. forget gate 값인 f 앞에 (1-r)이 붙음으로써 중요하면 중요할 수 록 forget gate의 값을 줄여주는 역할을 한다.
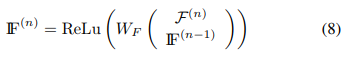
이때 F값 또한 반복적으로 학습되면서 W가 변화되어 좋은 attention weight를 찾도록 한다.
3) Learning the Classifier
마지막 interation 까지 F에 대한 학습이 끝나고 나면 다음과 같은 수식을 통해 최종 결과를 낸다.
<사족>
이 논문의 경우 앞선 논문에서 설명드렸던 단점을 일부 보완하는 구조를 보입니다. 즉, spatial 정보와 temporal 정보를 나눠서 attention을 구하는 것이 아닌 혼합적으로 구하기 때문에 둘 사이의 상관관계를 파악하는데 도움을 줄 수 있습니다.
반면 ST-LSTM 구조를 기본적으로 사용하기 때문에 joint 축에 대해서도 lstm 구조를 적용하게 되는데요. 제가 궁금한 것이자 단점이라고 생각하는 부분이 바로 여기입니다! joint의 위치 혹은 각도 정보는 어떤 sequential한 정보가 아니죠. graph 형식으로 dataset의 구조를 바꿔서 서로 연관성을 부여한다고 해도...아무래도 어떤 sequential data보다는 lstm에 적용하는 것이 좋을 이유가 없을 것 같습니다. 아무래도 3D 정보를 lstm에 적용하려고 하다보니 그렇게 된 것 같은데....왜 이렇게 한건지는 조금 더 찾아봐야할 것 같아요!(제가..찾고 싶어지는 날이 온다면....ㅎ...포스팅 하도록 하겠습니다)
그럼 이번 논문 리뷰도 여기서 마치겠습니다.
질문이나....오류가 있다면 댓글 언제든지 환영이에요!