* 본글의 모든 그림은 논문의 본문에서 가져왔습니다.
이번 요약하는 논문은 2017년 ICCV에 소개된 "Ensemble Deep Learning for Skeleton-based Action Recognition using Temporal Sliding LSTM networks" 입니다.
이전에 소개했던 논문들은 행동인식을 위해 특정한 방식으로 attention map을 구하고 적용했던 알고리즘이었습니다. 본 논문의 경우 이전 논문에서 얘기하는 그런 attention을 사용하는 논문은 아니구요, LSTM을 이용해서 학습을 하긴 할건데 어떻게 하면 기존의 LSTM의 문제점을 해결할 수 있을지에 대해 연구된 논문이라고 보시면 될 것 같습니다.
논문 전문 : http://openaccess.thecvf.com/content_ICCV_2017/papers/Lee_Ensemble_Deep_Learning_ICCV_2017_paper.pdf
[출처]Lee, Inwoong, et al. "Ensemble deep learning for skeleton-based action recognition using temporal sliding lstm networks." Proceedings of the IEEE International Conference on Computer Vision. 2017.
<개요>
3d depth 카메라를 이용해 얻어진 사람의 skeleton data를 바탕으로 한 행동인식에는 두가지 문제가 존재한다.
1. 크기, 방향, 시작점과 같은 데이터의 variation이 크다.
2. 사람 행동은 서로서로 유사하면서도 다양하고 다이나믹하다.
이 두 문제를 해결하기 위해 본 논문에서는 TS-LSTM을 제안한다.
먼저 data를 transformation 한다. 이 과정을 통해 모델이 크기, 방향, 시작점에 대해서 robust 해지도록 한다. 즉, 행동의 움직임의 방향이나 사람의 크기 등에 대해 다른 행동으로 인식되지 않도록 움직임의 방향, 크기 등을 맞추는 과정이다.
두번째로 관절의 위치 좌표를 사용하는 것이 아니라, 시간 축에 따라 움직임의 차이, 즉, velocity를 사용한다. 이는 네트워크가 실제 움직임 정보에 초점을 맞출 수 있도록 돕는다.
세번째로 멀티 스트림의 lstm에 위에서 추출한 motion feature를 넣는다. 본 논문에서는 Lstm을 짧은 시간 간격부터 긴 시간 간격까지 다양하게 선언을 하고 이러한 멀티 스트림을 마지막으로 앙상블해 결과를 낸다.
자세한 구조는 아래의 알고리즘 설명을 통해 확인해보자.
<알고리즘 설명>
1. Feature Representation
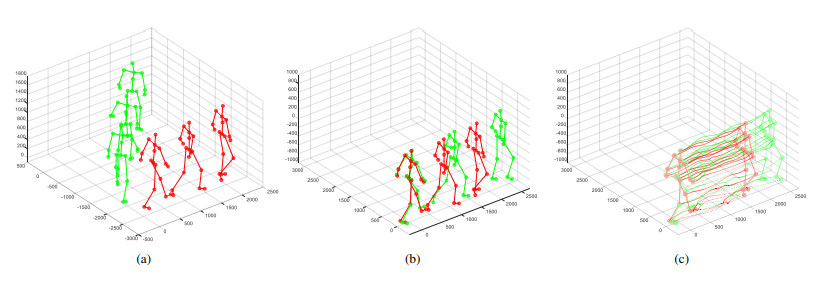
위의 그림에서 보이 듯이 기존의 skeleton input 값은 각기 다른 모습을 보인다. 즉, 같은 동작 class 안에서도 방향이 잘못 매칭 되어 있을 경우 전혀 다른 동작처럼 보일 수 있다. 따라서 이 문제를 해결하기 위해 (b)처럼 행동을 transformation합니다. Tranformation의 수식은 다음과 같다.
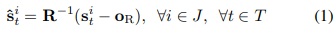

(1)번식의 경우 특정 rotation matrix에 원점으로 translation 된 좌표를 곱하는 것으로 R에 따라 skeleton의 방향이 바뀌게 된다. 즉, 그림(b)와 같이 시작점과 움직임의 방향을 맞춰준다.
(2)식을 보면 자세한 rotation matrix가 어떻게 동작하는지 알 수 있다. V1은 땅으로부터의 수직 벡터, v2는 hip left joint와 hip right joint의 차 벡터이다. 원점(O)은 두 hip 벡터의 중점이 된다.
(여기부턴 맞는지 확신이 없습니다....확실히 이해하신분은 댓글로 가르쳐주세요...ㅎ)
아래에 그림(직접그려 허접합니다..ㅎ)으로 잠시 이해해보도록 하겠다. 먼저 v1은 그림에서 빨간색으로 표시된 vector이구요. v2는 가로로 그려진 vector입니다. (2)식의 첫번째 텀이 v1의 단위벡터를 의미하니 즉, 해당 그림에서의 Y축 방향을 의미하게 됩니다. 두번째 (나)텀은 v1방향으로의 v2를 사영한 벡터를 v2에서 뺐습니다. 즉 X축 방향을 의미하게 됩니다. 마지막 (다)텀은 v1과 v2의 외적 단위벡터, 즉, Z축 방향을 의미합니다. 즉, 각각의 축의 방향을 보이는 R은 변환되기 전 현재 frame에서의 xyz축의 방향을 의미하는 것이다. 따라서 R의 역행렬을 구해 현재 위치에서 O기준으로 옮겨진 벡터(s-o)에 곱하면 새로운 좌표를 얻을 수 있다.

이렇게 옮겨진 skeleton은 각각의 frame의 차를 dataset으로 사용함으로써 (c)그림과 같은 모양으로 변경된다. Skeleton의 joint의 좌표는 현재의 위치에 중점을 두는 반면에, 두 frame을 빼서 얻은 motion feature의 경우 skeleton의 joint의 실제적인 움직임을 표현한다.
다음과 같은 방식으로 motion feature를 추출한다.
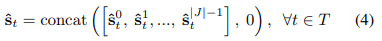

Transformation 과정을 거친 모든 joint의 값들을 (4)식과 같이 하나의 벡터로 합친다. 한 frame에서 skeleton의 모든 joint 좌표가 하나로 표현되면(s벡터) 그 벡터를 정해진 D값 만큼 떨어진 frame의 좌표 벡터와 빼 새로운 input vector인 x를 구한다.
2. Temporal Sliding LSTM
일반적으로 LSTM은 시간의 다이나믹스를 사용해왔다. 시간 축 상으로 멀리 떨어진 값들 간의 관계성을 파악하기 위해 forget gate가 추가되었지만 그럼에도 불구하고 완전하게 처리할 수 는 없다. 이러한 짧은 시간 단위에 대한 의존성을 해결하기 위해 TS-LSTM이 제안되어졌다.

TS-LSTM은 크게 3단계로 구성되었다. 첫번째는 window의 사이즈에 따라 LSTM의 개수가 정해진다. 이는 다양한 시간의 다이나믹스가 존재하는 행동을 classifying하는데 유용하다. 왜냐하면 lstm의 경우 max sequence를 기준으로 행동이 중간에 끝나면 그 결과를 사용하는데 ts-lstm의 경우 서로 길이가 다른 행동이어도 ts-lstm의 stride와 window 사이즈만 정해주면 동일하게 적용 가능하기 때문이다.

window사이즈에 따라 정해진 lstm들은 7개의 TS-lstm에 속한다. TS-LSTM 각각은 feature의 차를 구할때 얼마만큼의 차이를 두느냐에 따라 다르다. 즉, 위의 (5)번식에서 설명한 D값에 따라 나뉜다. L=0일 경우 short-term의 경우를 말하고 l=1,2인 경우 mid-term, l=3,4,5인 경우 long-term, 마지막으로 l=6인 경우 차를 두지 않고 포즈 데이터를 그대로 사용한 lstm이다.
3. Ensemble
각각의 결과를 앙상블 하여 최종 결과로 사용한다.
그 구조는 다음과 같다. 위 그림에서 보이듯이 각각의 ts-lstm을 통과한 시퀀스의 hidden state들은 concat한 후 sumpool, concat, linear, dropout, cross-entropy계산의 과정을 거친다.
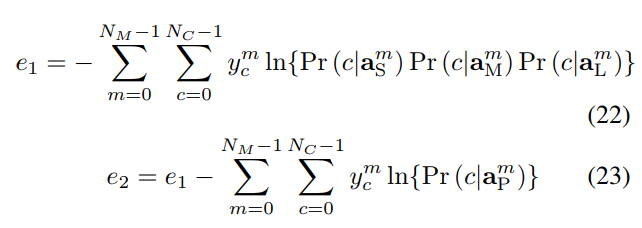
cross entropy 계산 과정을 통해 나온 결과들은 버전1과 버전2에 따라 서로 곱한다. (위의 22,23 수식에서 Pr은 각각의 term에서 계산되어진 cross entropy값이다.) 즉, 버전1의 경우 수식 (22)와 같이 3개의 값을 곱한 것에 자연로그(ln)를 씌워 계산한다. 버전2는 (22)에서 구한 값에 마지막 포즈를 이용해 구해진 TS-LSTM의 cross entropy값에 동일하게 자연로그를 씌워 계산한 것을 뺀다. 즉, cross entropy의 경우 전체의 확률의 합 중에 정답인 클래스의 확률이 얼마나 높으냐를 따지는 값으로 본 수식에서는 -가 붙어있기 때문에 작으면 작을 수 록 학습이 잘 된것으로 의미된다.
(22)의 경우 각각의 term들이 모두 크면 클수록 자연로그의 결과가 커지기 때문에 e1의 값은 결과적으로 작아지게 된다.
(23)역시 포즈를 이용한 마지막 term의 cross entropy 값이 클 수 록 잘 분류되었음을 의미하기 때문에 결과적으로 e2는 작아지게 된다.
backward의 과정은 (22)와 (23)이 더욱 작아지는 방향으로 학습하게 된다.
<사족>
제가 생각하는 이 알고리즘의 장점으로 말씀드리자면...
우선 행동인식에서 다양하게 존재하는 feature variation을 줄이기 위해 transformation을 썼다는 점, 그로 인해 dataset의 복잡도를 낮춰 네트워크가 학습을 쉽게 할 수 있도록 도왔다는 점이 있을 것 같습니다. 또한 lstm의 단점을 보완하고자 window 사이즈 별로 나눠진 여러 lstm을 계층적으로 사용해 정확도를 높였다는 것이 장점입니다.
반면 이 논문에서는 행동에서 spatial한 정보를 처리하기 위해서는 따로 처리를 하지 않고 lstm에 dataset을 입력하여 그대로 사용합니다. 따라서 어떤 특정 joint들 간의 관계성을 파악한다거나, 중요도를 찾아내는 것은 오로지 lstm의 하나의 layer에서 담당하고 있습니다. 이러한 부분을 개선할 수 있다면 더 좋은 정확도를 내는 것도 가능하지 않을까요?
이 논문의 경우 아주 반갑게도 공개된 코드가 있습니다.(사실 그래서 읽기 시작했어요ㅎㅎㅎ)
코드는 (https://github.com/InwoongLee/TS-LSTM) <- 여기서 다운이 가능합니다. 지금 코드를 돌려보려고 하는데....이상하게도 학습이 잘 안되네요ㅜ 무엇이 문제인지ㅜ 파악하고 있습니다...혹시나 코드 돌리는데 팁이 생긴다면, 함께 포스팅 해보도록 하겠습니다.
그럼 이번 논문 리뷰도 여기서 마치겠습니다.
질문이나....오류가 있다면 댓글 언제든지 환영이에요!
ps. 왜 중간내용은 '-이다' 체로 말하냐고 하신다면....논문 리뷰를 위해 정리할때 저렇게 정리해서 그렇습니다... 말투를 전부 바꾸는게 너무 귀찮네요ㅠ