* 본글의 모든 그림은 논문의 본문에서 가져왔습니다.
이번 요약하는 논문은 CVPR 2019에 나온 "An Attention Enhanced Graph Convolutional LSTM Networks for Skeleton-Based Action Recognition"입니다.
지난번 포스팅에 이어서 이번에도 CVPR에 나온 논문입니다. 역시나 최근의 행동인식 분야의 핫한 방식인 GCN을 사용한 논문이구요. 거기에 추가적으로 시계열 정보에 강세를 보였던 LSTM을 결합한데다가 attention까지 얹었습니다.
제가 그동안 리뷰했던 논문들의 알고리즘을 조금씩 섞었다고 보시면 될 것 같네요ㅎㅎㅎ
구체적으로 어떻게 적용하고 있는지는 아래의 설명을 통해 풀어보도록 하겠습니다.
논문 전문 : https://arxiv.org/pdf/1902.09130.pdf
[출처]Si, Chenyang, et al. "An Attention Enhanced Graph Convolutional LSTM Network for Skeleton-Based Action Recognition." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
<개요>
이전까지의 행동인식을 위한 논문들은 일련의 skeleton 값에서 시간, 공간의 특징들을 잘 찾아내기 위한 효율적인 모델을 찾기 위해 시도했다. 그럼에도 불구하고 얼마나 효율적으로 다른 공간과 시간의 특징들을 추출해내는가는 아직 어려운 문제이다.
일반적으로 사람의 일련의 skeleton은 다음과 같은 3가지 특징들을 갖고있다.
1) 각각의 노드들은 해당 노드의 인접 노드와 큰 관계성을 갖는다. skeleton의 틀이 몸의 구조적인 정보를 담고 있기 때문이다.
2) 같은 관절에서 뿐만 아니라 몸의 구조에서 시간상의 연속성이 존재한다.
3) 시.공간 사이에 동시출현의 관계성이 존재한다.
본 논문에서는 위의 3가지 특징들을 동기적으로(synchronously) 학습함으로써 skeleton 표현을 개선시킨 Attention enhanced graph convolutional LSTM network(AGC-LSTM)을 제안한다.
아래를 통해 각각의 알고리즘을 자세히 알아보자.
<알고리즘 설명>

위의 그림에서 개략적인 이 논문에 구조를 보여준다.
1. FC layer로 각 관절의 좌표를 spatial feature로 transform한다.
2. 위의 spatial feature와 현재 frame의 관절 값과 이전 frame의 관절 값의 차로 얻어진 velocity feature를 concat한다.
3. 합쳐진 feature를 관절 별로 LSTM에 넣어 새로운 값을 얻는다.
4. 얻어진 값을 이용해 AGC-LSTM network을 통과시킨다.
5. temporal averaging pooling을 통해 시간 축의 정보를 전역적으로 변경해가며 AGC-LSTM에 값을 넣어 classification을 한다.
각각을 자세히 살펴보자.
1. Joint Feature Representation
첫번째로 linear layer와 LSTM layer를 이용해 각 관절의 3차원 좌표를 고차원 feature space로 옮긴다. 고차원으로 값을 표현함으로써 그래프 학습에 유리하기 때문이다.
이를 위해 linear layer(FC)는 256 차원의 벡터로 관절 값을 인코딩한다. 이렇게 인코딩된 pose 벡터는 그래프에서 구조적인 feature를 잘 보여준다.
두번째로 위에서 얻어진 포즈 벡터를 근접 frame간의 값의 차를 구해 velocity feature를 추출한다. 이는 움직임의 dynamics를 보여준다.
두 feature를 모두 사용하기 위해 하나의 벡터로 concat한다. 하지만 두 feature 사이에는 크기에 대한 variation이 존재하기 때문에 이를 해결하기 위해 LSTM layer를 사용한다.

위의 수식과 같이, concat한 현재 frame의 각 관절의 pose 벡터(P), velocity 벡터(V)를 lstm에 넣어 E를 만든다. 이때 linear layer와 LSTM은 다른 관절끼리 서로 weight를 공유한다. 즉, 따로 처리하지만 동일한 모델로 학습된다.
2. Attention Enhanced Graph Convolutional LSTM
위의 과정을 모든 관절에 대해, 모든 시간축에 대해 처리하면 다음과 같은 Avg feature 벡터들을 얻을 수 있다.

얻어진 avg feature 벡터들은 아래의 그림과 같은 AGC-LSTM 네트워크에 입력된다.
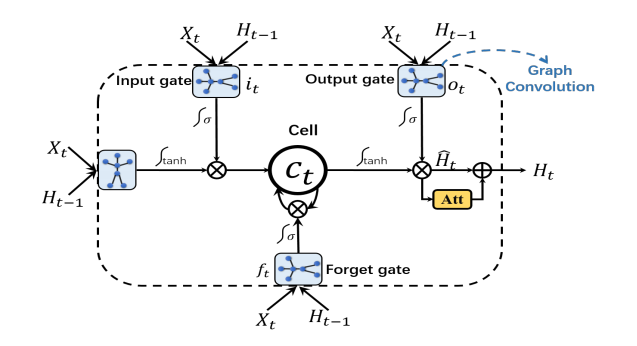
위의 그림과 같이 구성된 AGC-LSTM은 기본적으로 LSTM 구조에 linear layer로 연산되던 부분이 graph convolution 연산으로 변형된 모습을 갖고 있다. 그에 따라 아래와 같이 LSTM의 수식이 바뀐다. (* 연산이 graph convolution을 의미한다.)
이를 통해 이전 frame의 정보가 다음 frame의 feature를 추출하는데에 영향을 주는 LSTM의 장점을 살리면서 해당 frame의 feature를 추출하기위해 사람의 몸의 구조 데이터에 적합한 GCN을 사용할 수 있다.

LSTM의 연산이 graph convolution으로 변경된 것 뿐만 아니라, 중간에 attention 구조가 추가되었는데 이를 통해 특정 행동에서 특정 관절이 중요할 때 강조를 할 수 있다.

attention의 구조의 위의 그림과 같다. 위와 같은 연산을 통해 weight가 더해진 그래프를 얻을 수 있고, 이렇게 얻어진 그래프를 이용해 classification 된다.
3. Temporal Hierarchical Architecture
위의 AGC-LSTM 모듈을 총 3번 통과하는데 그 사이에 시간 축에 대해 pooling을 한다. 이 과정을 통해 시간축으로 receptive field를 늘려주게 된다. 즉, 해당 프레임과 AGC-LSTM연산을 하게 될 범위를 넓혀준다는 의미이다. 이렇게 함으로써 computational cost 또한 줄여줄 수 있다.
4. Loss Function
이렇게 학습된 AGC-LSTM 네트워크의 loss function은 다음과 같이 총 4개의 term으로 구성되어져있다.

첫번째 term은 attention이 추가되지 않은 global feature에 대한 cross entropy를 의미한다.
두번째 term은 attention이 추가된 local feature에 대한 cross entropy를 의미한다.
세번째 term은 모든 frame에서 한 관절의 값에 동일한 attention을 적용하는데 도움을 준다. 즉, attention이 너무 다이나믹 해지지 않도록 막는 term이다.
마지막 term은 관심 있는 joint의 개수에 제한을 둬 attention이 효용성이 있도록 돕는다.
학습이 끝난 후 마지막 classification을 할 때는 앞의 두개의 term만을 이용해 추정한다.
<사족>
이 논문의 경우 행동인식에서 가장 큰 문제인 시간,공간상의 feature 추출을 모두 훌륭하게 해냅니다.
반면 두 사이의 관계에 대해서는 LSTM과 GCN을 결합한 구조를 이용해 추출하고자 하지만 아무래도 모호하게 접근하게 되는 것 같습니다.
직접 코드를 돌려보면서 결과를 확인해보면 좋겠지만...아쉽게도 코드를 공개할 수 없다고 하네요.
그럼 이번 논문 리뷰도 여기서 마치겠습니다.
질문이나....오류가 있다면 댓글 언제든지 환영이에요!