* 본글의 모든 그림은 논문의 본문에서 가져왔습니다.
[AAAI-2018]Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
* 본글의 모든 그림은 논문의 본문에서 가져왔습니다. 이번 요약하는 논문은 AAAI 2018에 나온 "Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition"입니다. 최근(작년부터?)..
reading-cv-paper.tistory.com
일전에 위 논문에 대한 리뷰를 했었습니다. 위 논문의 경우 사람의 몸의 구조가 그래프와 유사하다는 점을 이용해 GCN을 사용하는 알고리즘이었죠. 논문 제목을 줄여 해당 알고리즘을 ST-GCN이라고 부릅니다.
이 논문이 갖고있는 단점을 해결하고자 같은 연구실에서 바로 다음 논문을 발표했었습니다. ST-GCN을 개선 시킨 AS-GCN입니다. (자세한 궁금하신 분들은 링크를 통해 확인해주세요ㅎㅎ)
[CVPR-2019]Actional-Structural Graph Convolutional Networks for Skeleton-based Action Recognition
* 본글의 모든 그림은 논문의 본문에서 가져왔습니다. 이번 요약하는 논문은 CVPR 2019에 나온 "Actional-Structural Graph Convolutional Networks for Skeleton-based Action Recognition"입니다. 지난번 포스팅..
reading-cv-paper.tistory.com
위의 논문과 동일하게! 2019년 CVPR에 올라온 다른 논문이 바로 오늘 소개해드릴 논문인 "Two-Stream Adaptive Graph Convolutional Networks for Skeleton-Based Action Recognition"입니다.
이 논문 또한 base line을 앞선 ST-GCN으로 잡고 있구요. 문제점을 해결하고자 하는 방향 또한 굉장히 유사합니다.
언급한 것과 같이 ST-GCN 논문에 문제점을 보완했기 때문에 논문에 대해 이해를 높이기 위해 ST-GCN 논문을 먼저 보시고 이 글을 읽는 것이 좋습니다. 따라서 위에 참조해놓은 ST-GCN의 리뷰를 먼저 읽고 본 글을 읽어주세요.
성능면에서 비교해보면 오늘 소개해드릴 논문이 정확도가 조금 더 높습니다.
앞서 리뷰했던 논문과 달리 어떤 방식으로 알고리즘이 구현되어서 좋은 성능을 보이는지 자세히 알아보도록 하겠습니다.
[출처] Shi, Lei, et al. "Two-Stream Adaptive Graph Convolutional Networks for Skeleton-Based Action Recognition." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
<개요>
기존의 ST-GCN의 알고리즘의 경우 graph 구조를 이용하여 시간, 공간상의 관계성을 찾아내고 행동을 분류한다는 novelty가 있었다.
반면 ST-GCN은 몇가지 문제점을 갖고있다.
- ST-GCN의 경우 local 영역에서의 관절간의 관계성 밖에 찾지 못한다.
- ST-GCN의 경우 topology가 고정되어있기 때문에 기존의 GCN이 갖고 있는 계층적인 특성을 갖지 못한다.
- 고정된 그래프 구조는 모든 sample들에게 최적화 되어있지 않다. 즉, 얼굴을 쓸어내리는 동작의 경우 손과 머리의 관계성이 중요한데에 비해 점프하는 동작은 그렇지 않다. 이러한 부분들이 ST-GCN에서는 반영되지 않는다.
본 논문에서는 이 세가지 문제를 해결하기 위해 연계되어 학습되는 2개의 그래프를 생성한다.
- global graph : 모든 data에 대해 공통적인 pattern을 표현한다.
- individual graph : 각각의 data에 대해 독특한 pattern을 표현한다.
이 외에도 ST-GCN의 경우 사용하는 data가 1차원이라 두 관절사이의 뼈에 대한 정보가 포함되어 있지 않다. 행동인식에서 이 뼈들의 방향 혹은 길이 등이 중요한 정보를 제공한다.
이 정보를 포함하기 위해 본 논문에서는 2차 data를 생성해 two stream으로 학습을 진행한다.
각각의 graph의 구조에 대해 자세히 알아보자.
<알고리즘 설명>
1. Adaptive graph convolutional layer
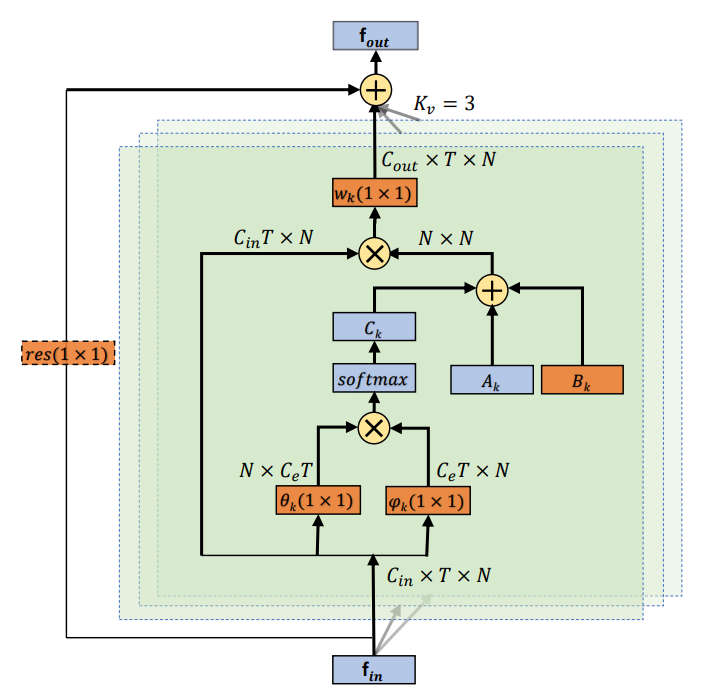
앞서 설명한 문제점들을 해결하기 위해 다음과 같은 구조의 GCN을 제안한다. 이 구조는 end to end 학습 방식으로 네트워크의 다른 파라미터들과 함께 최적화된 그래프의 topology를 만든다.


(2)번식의 경우 기존의 GC을, (3)번은 AGC을 나타낸다. 기존의 GCN과 대비하여 새로 생긴 term들이 바로 위에서 언급한 학습을 통한 GCN의 계층적 구조를 강조시키는 부분이된다. 각각에 대해 자세히 알아보자.
1) A_k
이 matrix는 이전의 GCN에서의 인접행렬과 동일하다. 따라서 각 관절이 연결된 바로 옆의 관절들을 인접행렬로 표현한 것이다.
2) B_k
Ak와 동일하게 인접행렬을 의미한다. 단 Ak와 다르게 학습을 통해 인접된 관절이 결정된다. 이로써 행동을 구별하는 일에 좀 더 초점이 맞춰지고 또한 다른 layer에서 포함된 다른 정보들에 대해 더 개별화된다. 또한 학습하는 과정에서 두 관절의 연결성에 대해서 배우는 것 뿐만 아니라 어느 정도 연결이 되어 있는지 그 정도에 대해서도 학습 가능하다. 따라서 attention의 효과도 함께 볼 수 있다. 하지만 기존의 attention 모듈의 경우 인접행렬에 attention matrix를 곱하는 형식으로 존재했다. 이 경우 인접행렬의 특정 값이 0일 경우 attention 값에 관계없이 늘상 0이 된다. 따라서 기존의 물리적인 그래프에서 새로운 연결을 만드는 것은 불가능했다. 이러한 문제 역시 Bk를 더함으로써 해결 가능해진다.
3) C_k
마지막으로 Ck의 경우 data에 의존적인 그래프로, 각각의 sample에 대해 독특한 그래프를 배운다. 두개의 관절을 연결을 할지 결정하기 위해 두 관절의 feature vector를 곱해 얼마나 두 관절이 유사한지 계산한다. 해당 function에 넣기 전 1X1 convolution을 이용해 space를 옮겨준다.
위의 3가지 인접행렬들을 이용해 graph convolution을 함으로써 한번의 AGC의 과정이 끝난다.
2. Adaptive graph convolution block

Adaptive graph convolution block은 위에와 같이 구성된다. Convs는 spatial 축을 따라 AGC를, Convt는 temporal 축을 따라 AGC를 하는 것을 나타낸다.
3. Adaptive graph convolution block(AGCN)

최종 AGCN의 구조는 다음과 같이 AGC block을 총 9번 거친다. 9번을 거친 후 softmax 함수를 이용하여 행동의 클래스를 분류한다.
4. Two-stream networks

<개요>에서 언급했던것과 같이 행동인식에서는 각 관절 data의 1차원적인 정보도 중요하지만 관절이 연결되어 만들어진 뼈들의 방향과 길이 정보 또한 중요하다. 해당 정보를 담기 위해 2차 data를 생성하고 그에 해당하는 stream을 따로 만들어 두 결과를 합쳐 최종 label를 결정한다.
뼈에 대한 정보는 다음과 같은 방식으로 계산된다.
먼저 인접해있는 두 관절 중 몸의 중심에 더 가까운 관절을 source joint라 하고 그렇지 않은 관절을 target joint라 한다. 해당 두 관절을 빼서 vector를 만든다. 그래프 구조는 cycle 구조가 없어야하므로 각각의 bone은 서로 다른 target joint를 갖는다. 이때 중심 관절은 bone을 만들때 사용되지 않아 joint의 개수보다 하나가 적게 된다. joint와 bone의 개수가 달라지면 network를 구성함에있어 복잡해질 수 있으므로 가상의 bone을 하나 추가한다.
구해진 bone을 이용해 B-stream을 학습시키고 joint를 이용해 J-stream을 학습시킨다.
<사족>
같은 시기에 같은 문제점을 풀기 위해 두가지의 논문이 나왔습니다. 오늘 소개드린 논문이 이전의 AS-GCN보다 조금 더 좋은 성능을 보이는데 아무래도 AS-GCN에는 없는 layer 별로 topology를 바꿀 수 있는 Bk가 있기 때문이 아닐까 싶습니다.
하지만 여전히 시간 축에 대한 계산과 공간상의 계산을 따로 함으로써 특정 시간에서의 특정 관절간의 관계의 중요성이 드러나지는 않은 것 같습니다.
이 논문 또한 코드가 공개되어있습니다.
코드 : https://github.com/lshiwjx/2s-AGCN
아무래도 같은 base line을 사용하다보니 코드 또한 유사합니다. 아직 돌려보지는 않아 레포팅된 수치가 나오는지는 확인하게 된다면 수정해서 올리도록 하겠습니다.
추가로 잡담하나 말하자면 충격적이게도 동일한 저자가 행동인식이라는 주제로 CVPR 2019에 논문 두개가 accept 되었더라구요... 될놈될...ㅎ... 그 논문도 읽게 된다면 또 리뷰하도록 하겠습니다ㅠ
그럼 이번 논문 리뷰도 여기서 마치겠습니다.
질문이나....오류가 있다면 댓글 언제든지 환영이에요!