* 본글의 모든 그림은 논문의 본문에서 가져왔습니다.
오늘은 좀 더 거슬러 올라가, OpenPose에 대해 설명해볼까 합니다. 이 논문의 경우 2D 이미지에서 사람의 skeleton을 찾는데에 정말 좋은 성능을 보이는, 당시에 정말 충격적인 성능을 보여준 논문입니다. 저자가 코드도 잘 짜두었고, 파이썬으로도 쉽게 사용할 수 있도록 되어있어, 아마 많은 분들이 이미 한번 사용해보셨을 수 도 있을 것 같네요!
그럼 어떤 방식을 취했길래 좋은 성능을 보였는지에 대해 설명해보도록 하겠습니다.
+ 이 논문의 경우 두가지 버전이 있습니다. 먼저 나온 것은 CVPR 2017에 소개된 버전인데요. 저는 그것보다 TPAMI에서 발표된 저널 버전으로 설명하도록 하겠습니다. 이 버전이 좀 더 성능이 좋고 속도 또한 개선되었습니다.
논문 전문 : https://arxiv.org/pdf/1812.08008.pdf
[출처] Cao, Zhe, et al. "OpenPose: realtime multi-person 2D pose estimation using Part Affinity Fields." arXiv preprint arXiv:1812.08008 (2018).
+ 설명하다보니, limb을 어떻게 해석할까 애매하여.... 본 포스팅에서는 뼈라고 했습니다....ㅎㅎ 그냥 관절간에 연결된 뼈, 혹은 edge 혹은 연결선이구나 생각하시면 됩니다...ㅎㅎㅎ
<개요>

위의 [그림 1]에서와 같이 한장의 이미지에서 사람의 관절을 찾는 일에는 여러가지 어려운 점이 존재합니다.
1. 이미지내에 몇명의 사람이 등장하는지 알 수 없다는 점.
2. 여러 사람이 등장함으로써 서로의 관절이나 팔다리가 가릴 수 있다는 점.
3. 한 장에 등장하는 사람이 많으면 많을 수 록 처리하는 시간이 오래걸린다는 점.
이런 어려운 문제를 극복하고 여러 사람의 관절을 찾아주는 알고리즘에는 크게 두가지 방식이 있는데요.
단순하게 top-down 방식으로 먼저 사람이 몇명이 있는지 이미지에서 찾고, 한 사람 한사람의 관절을 찾아줄 수 있습니다. 단, 이 방식의 경우, 먼저 사람을 잘못 검출하게 되면 복구될 가능성이 조금도 생기지 않습니다. 또한 한 사람, 한 사람 각각에서 관절을 찾기 때문에 사람의 명수에 따라 처리 시간이 기하급수적으로 늘어나게 됩니다.
이러한 문제점을 극복하고자 이 논문에서는 bottom-up 방식을 사용합니다.
즉, 한 장의 사진에서 먼저 각각의 관절에 대한 정보(각각의 관절의 위치와 팔다리의 방향)를 찾고 이 관절이 어떤 관절과 연결되는지 찾아 하나의 사람으로 만들어 주는 것이죠. 이 방식의 경우 성능에 대해서도 어느정도 robustness를 보장해주면서, 많은 수 의 사람들이 등장해도 한 명일때와 다르지 않게 처리가 가능합니다. 물론, 이전의 bottom-up방식을 이용한 알고리즘들의 경우 시간이 굉장히 오래걸리는 단점이 있었습니다만...
이 논문에서 어느정도 해결이 되었습니다.
그렇다면, 구체적으로 어떤 흐름으로 알고리즘이 구현이 되었는지 한번 알아보도록 하겠습니다.
<알고리즘 설명>

전반적인 흐름은 [그림 2]에서 보이는 바와 같습니다.
1. 이미지에서 Part Affinity Fields와 Part Confidence Maps 검출하여 관절을 찾아줍니다.
2. 찾아진 관절간의 관계성을 찾아 matching 해줍니다.
각각이 무엇인지 자세히 살펴보도록 하겠습니다.
1. Part Affinity Fields / Part Confidence Map

Openpose에서는 먼저 PAFs(Part Affinity Fields) 와 Part Confidence Map을 찾아줍니다.
각각은 그림에서 처럼 관절의 위치에 대한 heat map과 뼈에 대한 정보를 담고 있는 heat map이라고 보시면 됩니다.
이 두가지를 찾는 모델의 구조의 위의 [그림 3]에서와 같이 구성됩니다.
파란색 부분이 PAFs를 추출하는 부분이고, 빨간색 부분이 Confidence Map를 추출하는 부분입니다.
전체적으로 보면, 먼저 이미지를 VGG 네트워크를 이용하여 feature F를 추출합니다. 추출된 F를 입력값으로 사용하여, convolution 연산을 통해 먼저 PAFs를 추출합니다.
이때 PAFs의 dimension은 총 (h' X w' X 관절 개수 X 2) 가 됩니다. 즉, 왼쪽 lower arm 에 해당하는 heat map 한장, 왼쪽 upper arm에 해당하는 heat map 한장 이런식으로 구성되는 것이죠.
또한 [그림 2]에서 보이다시피 PAFs는 vector로 구성됩니다. 예를 들어 오른쪽 upper arm에 대한 PAF를 추출한다면, 팔꿈치와 어깨 사이의 픽셀들의 값이 팔꿈치를 향하는 2차원 벡터로 구성되는 것입니다.
PAFs는 한번의 과정을 거쳐서 나오는 것이 아니라, 여러번의 stage를 거쳐서 나옵니다.
[그림 3]에서 파란 박스의 윗 부분에 나오는 것이 바로 이 stage에 대한 정보인데요. 정해진 만큼의 루프를 돌면서 좀 더 정밀하게 PAFs를 찾을 수 있도록 하는 것입니다.
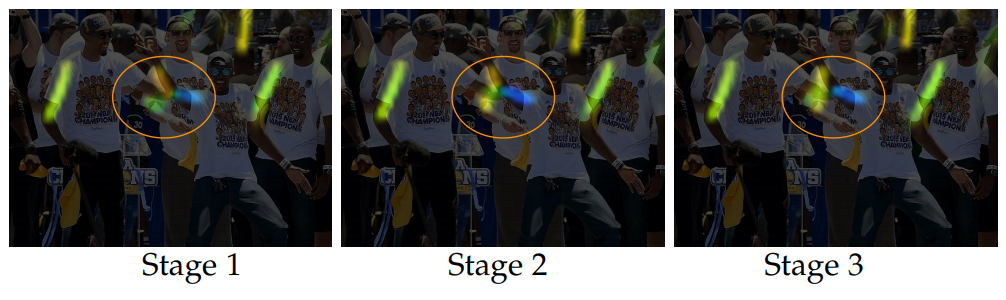
[그림 4]에서는 stage에 따른 PAFs의 개선되는 방향을 보여줍니다. 그림에서 보이듯이, 잘못 찾은 부분은 점차 사라지고, 찾지 못했던 부분은 정확하게 찾아지는 것을 확인할 수 있습니다.
최종적으로 구해진 PAFs는 원래의 F와 값이 더해져 Confidence Map를 구하는 과정으로 넘어가게 됩니다.
여기서의 모델 구조는 앞의 PAFs와 동일합니다. 다만 dimension의 차이가 생깁니다.
PAFs의 경우 벡터 값을 heat map으로 표현해야했기 때문에 confidence map 보다 2배 더 많게 됩니다. 따라서 Confidence map의 dimension은 총 (h' X w' X 관절 개수) 가 됩니다.
Confidence map 역시, PAFs에서와 같이 여러번의 stage를 거쳐 최종 결과를 줍니다.
앞서 말씀드렸듯이, 이 논문은 크게 CVPR에서 발표된 구버전의 논문과, TPAMI에 소개된 현 버전의 저널이 있는데요. CVPR의 버전에서는 위의 그림과 같이 모델의 구조가 직렬로 붙어 있는 것이 아닌, 병렬 구조로 연결되어있었습니다. 이와 같이 변경함으로써 성능과 속도 두가지에서 모두 이득을 취했는데요.
두 모델을 병렬로 처리하지 않아도 되기 때문에 메모리 면에서 이득을 취했고 이로 인해 속도를 올릴 수 있었습니다.
또한 PAFs의 값을 confidence map을 구하는 데에 넣어주게 되는데, 이 과정에서 정확도도 함께 올라가게 되었습니다. 논문의 저자는 우선 PAFs를 알고나면 관절의 위치를 찾는 것은 훨씬 쉬운 일이 되기 때문에 네트워크의 성능이 올라가게 된다고 합니다. 쉽게 말해서 upper arm의 위치를 알면 그 방향성에 따라 어깨와 팔꿈치의 위치를 예측하는 것은 매우 쉬운일이 되죠.
2. Part Affinity Fields
PAFs가 없이 pair가 되는 두 관절을 찾는 것은 사실상 많은 제약이 존재합니다.

[그림 5](b)에서 볼 수 있듯이, PAFs가 없는 상태에서 pair를 찾기 위해서는 각각의 중심점을 찾고 연결을 해주는 방식입니다. 하지만 중심점을 찾아서 연결하게 되면, 이미지가 복잡한 경우에는 잘못된 pair를 찾을 가능성이 높아집니다.
이러한 한계점을 PAFs를 이용하면 해결이 가능합니다. 두 관절 사이의 방향에 대한 정보를 vector 값으로 갖고 있기 때문에 해당 방향에 맞는 관절과 pair를 해주면 되는 것이죠.
PAFs를 학습시켜 추출해내기 위해서는 우선 ground truth data가 필요합니다. 이 부분을 계산하기 위해 본 논문에서는 다음과 같이 계산하였습니다.

위의 그림처럼 ground truth의 관절 위치가 주어지면, 각각의 관절 사이의 pixel들에 대해 뼈 위에 존재하는지 안하는지에 대해 판단합니다. 이 판단을 위해서 다음 수식을 사용합니다.

쉽게 풀어서 설명하자면, 초록색의 벡터의 길이가 두 관절 사이의 거리보다 크거나 작을 경우, 초록색 벡터와 두 관절을 이은 벡터 사이의 각도가 특정 한계치의 값보다 크거나 작을 경우 모두 예외처리 해줍니다. 즉, 적정 범위 안에 있는 픽셀들에게 v의 단위 벡터 값을 부여하는 것이죠.

만약, 똑같은 upper arm에 대해 두가지 후보가 존재하여 vector가 겹칠때!를 처리하기 위해 구해진 ground truth 값들은 각각 픽셀에 대해 평균을 구해 정합니다.
(사실 이 부분에 대해서는 왜 그렇게 하는지 잘 이해가 안갑니다..어쩔 수 없이 저렇게 정한 것 같긴 한데....완전 이상한 값이 나올 수 도 잇을것 같은데 참...)
이렇게 구해진 ground truth data를 이용하여 학습을 하는데, pair의 후보인 관절을 연결하는 뼈 위에 있는 것으로 예상되는 pixel들의 모든 PAF 값을 적분하여 E값을 구합니다.


쉽게 바꿔 설명하자면, 뼈 위에 있을 것으로 예상되는 pixel들의 모든 벡터 방향과 두 후보 관절간의 단위 벡터의 방향이 일치할 수 록 E의 값이 커지게 되는 것이죠. 이때 관절 위에 있을 것이라고 유추되는 픽셀들은 아래의 p(u)를 통해 구해냅니다.
결국 E가 크면 클 수 록 관절을 잘 이었다는 것이 됩니다.
3. Multi-Person Parsing using PAFs
이렇게 두 관절 간의 pair를 찾았으니, 이제 뼈들의 조합을 찾아 한 사람의 skeleton을 만들어줘야합니다.
먼저, 각각의 body part의 후보들이 각자의 E값의 weight를 갖고 있습니다.
여기서 관절의 pair를 찾았던 것 마냥, body part들의 pair도 찾아줘야합니다. 즉, 한 사람의 upper arm과 lower arm을 찾아 매칭시켜줘야 한다는 것이죠.
만약, 한 사람만 있는 경우라면 고민할 것 없이 그저 E가 높은 관절을 서로 연결해주면 됩니다. 하지만 Openpose에서 해결하려고 하는 문제는 multi people의 경우기 때문에, 좀 더 복잡합니다.

위 수식에서 말하고자 하는건 결국, 연결하고자 하는 body part에 동일한 node가 존재하지 말아햐하고(이게 된다면, 한 사람의 몸에 오른쪽 upper arm이 두개가 있는 경우가 되겠죠.) 또 E의 값을 최대화 시켜줄 수 있는 pair를 찾는 것입니다.

여기서 한가지 속도를 높여줄 제약조건이 붙는데요. 다른 그래프에서의 문제와는 다르게, 사람의 포즈를 찾는 알고리즘의 경우 몇가지 제약조건을 걸어 문제를 쉽게 할 수 있습니다.
1. 어쨋든 사람의 몸이므로 연결될 수 있는 body part는 정해져 있습니다. (즉, upper arm과 lower arm이 연결 될 것이지, 갑자기 오른발과 upper arm이 붙지는 않을 것이라는거죠.)
2. 모든 노드를 전부 연결하고 계산하지 않고 [그림 7](d) 에서 보이는 것 처럼 나눠서 계산합니다. 그 다음 동일한 노드를 가지는 애들끼리 연결해주는 것이죠.
뿐만 아니라, CVPR 버전의 논문에서 한가지가 더 추가가 되었는데요. 바로 redundant PAF connection을 포함시킨 것입니다. redundant PAF connection은 예를 들어 귀와 어깨, 손목과 어깨과 같은 것들로 구성됩니다. 이 부분을 추가시킴으로써 기존의 결과에 비해 사람이 혼잡할 경우에 더 정확하게 pose를 찾아주게 됩니다.

이 부분은 위의 사진을 보면 그 효과를 확인할 수 있습니다. 기존에 얼굴을 잘못 찾음으로써 [그림 8](a)의 노란색 부분이 잘못 연결된것을 확인할 수 있습니다. 반면, (b)에서는 보라색의 어깨와 오른쪽 귀를 연결해주는 edge로 인해 올바르게 얼굴과 목이 연결되었습니다.
이러한 방식을 접목시키기 위하여, 이전 버전에서는 root에서부터 connection을 찾아 body part를 연결해줬더라면, 이 논문에서는 모든 pair를 찾고, 만약 동일한 연결이 동시에 발생할 경우 high confidence를 갖고 있는 부분을 살려주게 됩니다.
<사족>
이 논문은 결국 여러사람이 등장하는 이미지에서, 사람의 명수를 알지 못해도 정확하게 한 사람의 pose를 찾아준다는 점이 엄청난 장점이 됩니다. 그것도 사람 수에 독립적으로 일을 하기 때문에 속도도 크게 늘지 않구요.
논문 내에서 결과를 보시면 아시겠지만, pose estimation의 성능을 드라마틱하게 올려놓았습니다. 실제로 제가 실험을 직접 돌려보았을 때도 가려진 부분이 있는 곳에서도 결과가 꽤 괜찮게 나왔습니다.
문제점은...사실 저도 아직 잘 못 찾았는데...
아시는게 있다면 댓글로 알려주세요ㅋㅋㅋㅋㅋㅋ
이 논문 또한 코드가 공개되어있습니다.
코드 : https://github.com/CMU-Perceptual-Computing-Lab/openpose
코드 뿐만 아니라, 패키지로 쉽게 설치하여 간단하게 실험을 해보는 것도 가능합니다.
아마 많은 pose estimation 하시는 분들이 간단히 돌려보셨을 것이라고 생각합니다.
그럼 이번 논문 리뷰도 여기서 마치겠습니다.
질문이나....오류가 있다면 댓글 언제든지 환영이에요!